Cvpr 2025 Tutorial On Prompting In Vision
Cvpr 2025 Tutorial On Prompting In Vision. Foundation models + visual prompting are about to disrupt computer vision; Contact cvpr help/faq my stuff login.
Cvpr 2025 On Prompting In Vision Dede Monica, The 2025 conference on computer vision and pattern recognition (cvpr) received 11,532 valid paper submissions, and only 2,719 were accepted, for an overall acceptance rate of about.
Cvpr 2025 On Prompting In Vision Fae, In this tutorial, our aim is to provide a comprehensive background on prompting by building connections between research in computer vision and natural language processing.

Cvpr 2025 On Prompting In Vision Fae, Except for the watermark, they are identical to the accepted versions;

Cvpr 2025 On Prompting In Vision Carley Eolanda, Foundations and applications sijia liu · yang liu · nathalie baracaldo · eleni triantafillou jun 17, 9 a.m.

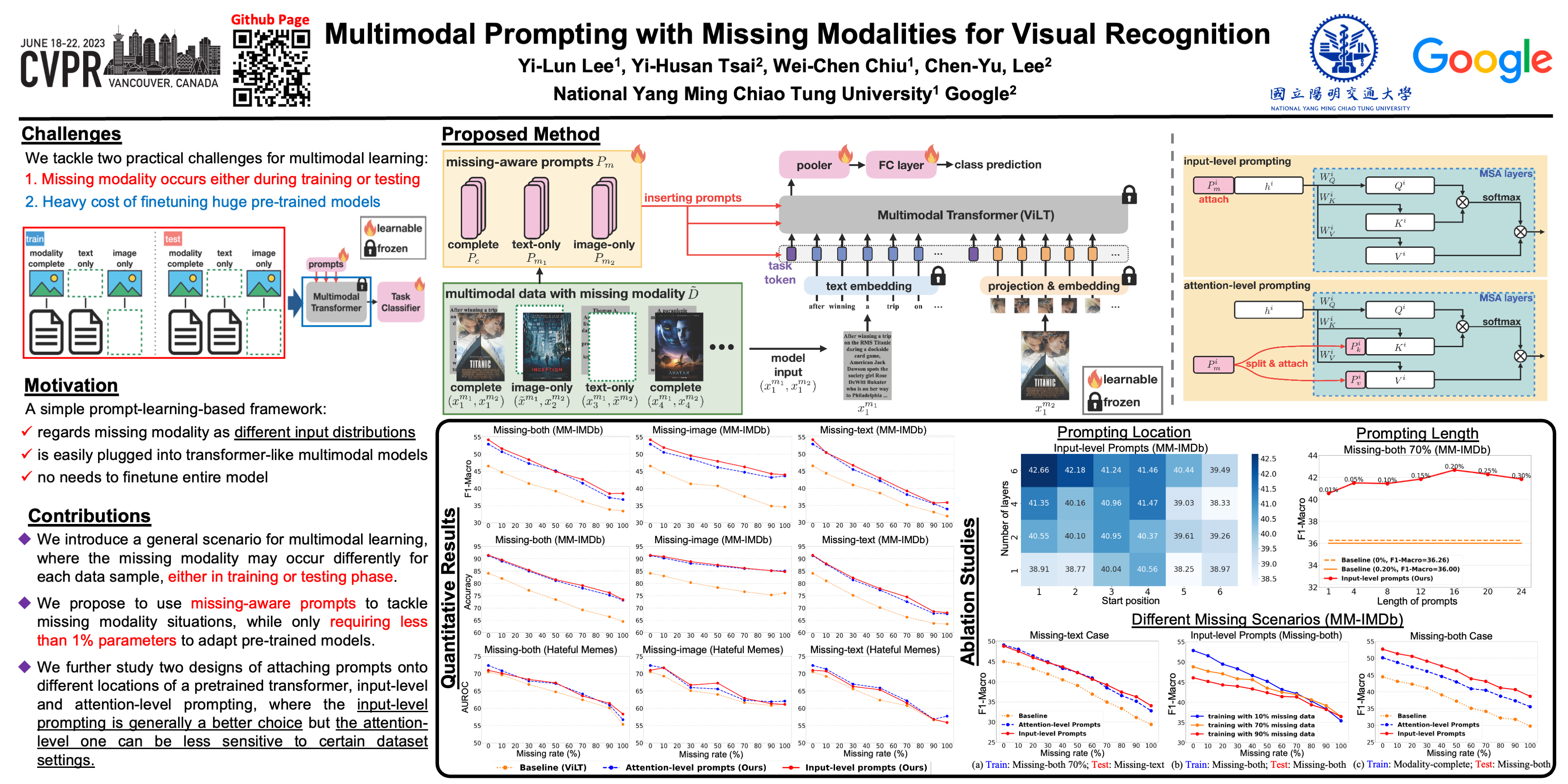
CVPR Poster Multimodal Prompting With Missing Modalities for Visual, @inproceedings {ape, title = {aligning and prompting everything all at once for universal visual perception}, author = {shen, yunhang and fu, chaoyou and chen, peixian.

Jack Langerman CVPR on Twitter "RT liuziwei7 CVPR2023 Our, This workshop aims to provide a platform for pioneers in prompting for vision to share recent advancements, showcase novel techniques and applications, and discuss open research.
Jack Langerman CVPR on Twitter "RT liuziwei7 CVPR2023 Our, 🔥 learn more about visual prompting and rag:

【CVPR 2025】Openset Finegrained Retrieval via Prompting Vision, Below are, in no particular order, five papers from cvpr 2025 that i feel are set to redefine the intersection of computer vision and natural language processing.

CVPR2023 Tutorial Prompting in Vision笔记 Kamino's Blog, In this tutorial, our aim is to provide a comprehensive background on prompting by building connections between research in computer vision and natural language processing.

[CVPR 2025] TextVisual Prompting for Efficient 2D Temporal Video, These cvpr 2025 workshop papers are the open access versions, provided by the computer vision foundation.
